
Why Mask Guard?
We are living in the dangerous and uncertain time of a pandemic. A huge amount of SMBs has been closed down by the authorities during the pandemic. Do you also want to be one of them because your business has been declared a super spreader location? Of course not! And thats why we invented the MaskGuard, a Mask-No-Mask detector that detects if your customers are wearing a mask or not and only lets them enter your business if they are wearing one. Our highly educated team put all their knowledge in deep learning and computer vision together to create a tool that gives you one thing that lets you and also your customers sleep well at night: SECURITY!




The potential places in which Mask Guard will be used differ a lot and so will the lighting conditions. To prepare the detector as best as possible for different environments we implemented an image optimization stage. In the current version of Mask Guard the optimizer uses adaptive contrast stretching. Therefore the frame is splitted into H, S, and V channel to adjust the original image depending on the mean pixel value in the V channel.

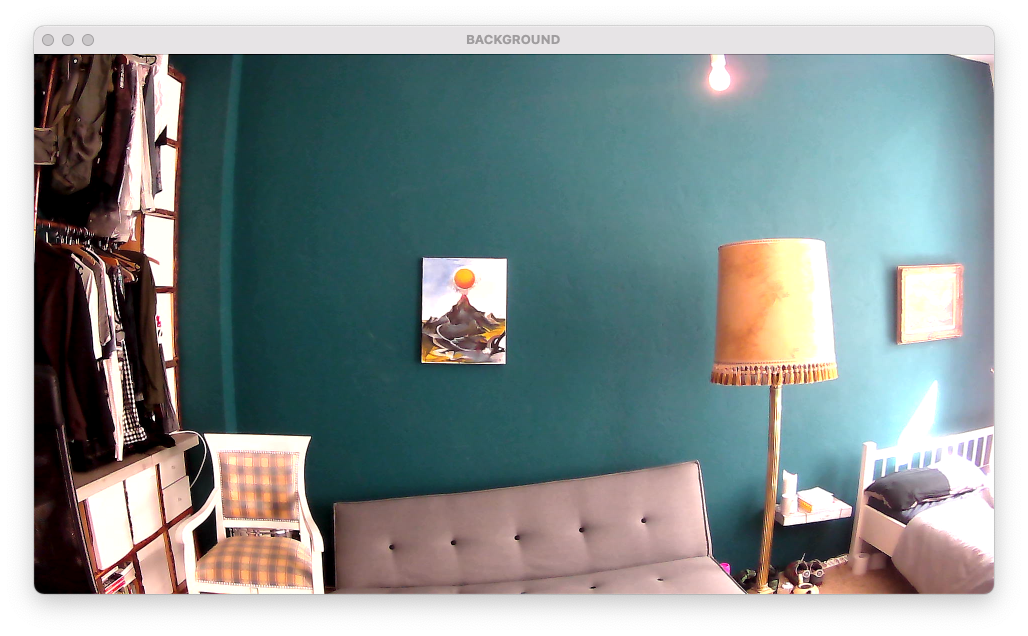
The motion detector first captures an image of the background to later isolate only the moving parts in the image. The motion detector only works on a static camera such as CCTV.
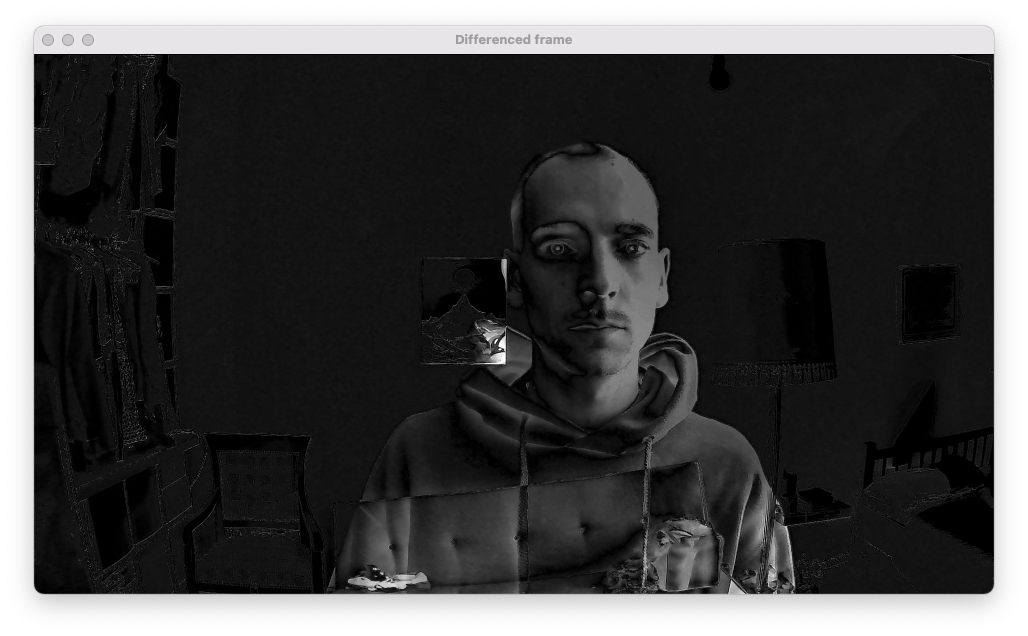
To isolate only the elements in the image that are moving cv2.absdiff() is used. The output image still contains some noise that need to be erased in the next steps.
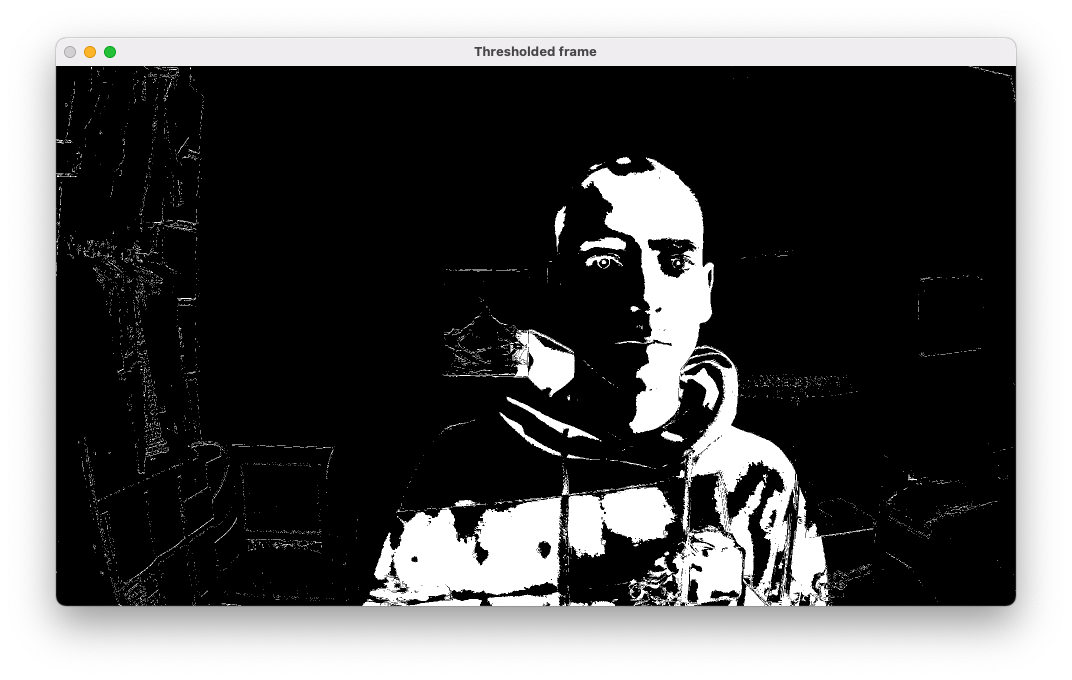
The difference between background and current frame now gets thresholded so that pixel values above 50 will be 255 (white) and pixel values below 50 will be 0 (black)
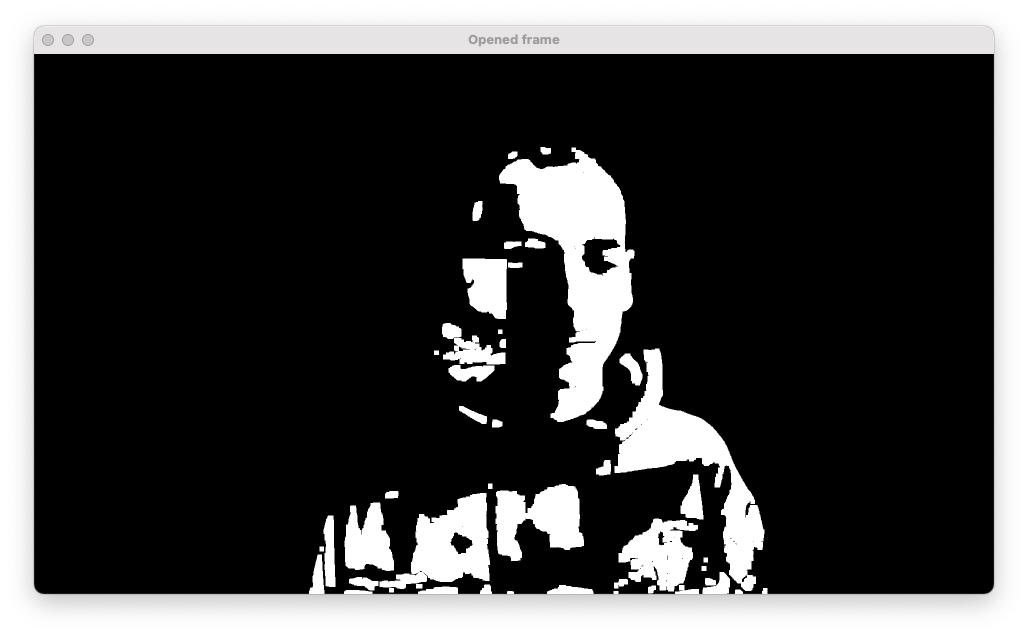
To reduce the remaining small noise on the thresholded image even more a combination of erosion and dilation ('opening') is used.
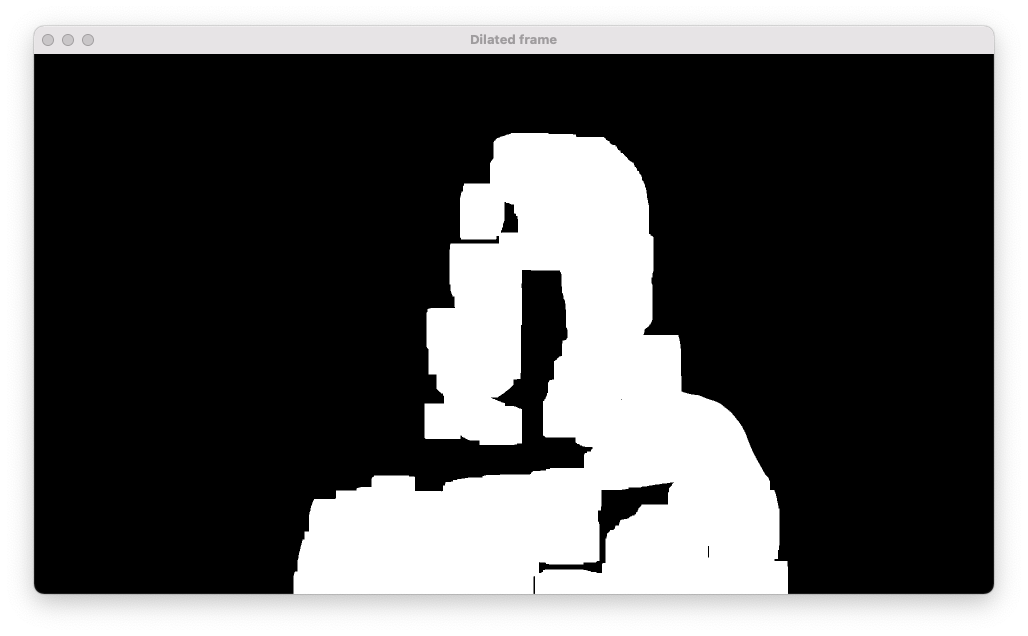
So far the recieved image is a bit scattared. To generate clearer areas of interest the opened image gets dilated a lot more.

In this step cv2.findContours() finds the contours of all elements that differ between background and current frame.

Bounding rectangles recieved from the found contours are saved to crop the original image into small parts that probably contain faces and should be send to the face detector.
Face detection in general is a popular topic in biometrics and still evolves quickly. There are tons of surveillance cameras in public places and businesses which deliver a huge amount of images for face detection. The most important bottlenecks in applications like this are speed and accuracy to detect faces. In general the face detection network gets a BGR image (in our case a frame of the webcam stream) as input and produces a set of bounding boxes that might contain faces. All we need to do is just select the boxes with a strong confidence. Our face detector is based on a SSD framework (Single Shot MultiBox Detector), using a reduced ResNet-10 model.
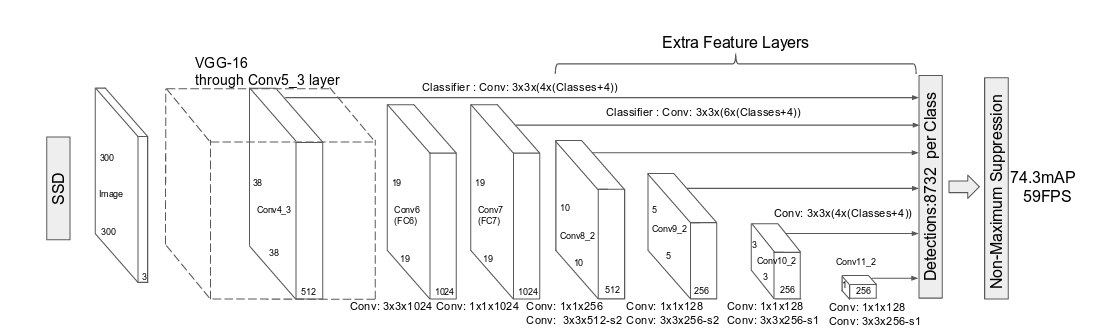
A Single-shot MultiBox Detector is a one-stage object detection algorithm. This means that, in contrast to two-stage models, SSDs do not need an initial object proposals generation step. This makes it, usually, faster and more efficient than two-stage approaches such as Faster R-CNN, although it sacrifices performance for detection of small objects to gain speed.
Deep Residual Networks (ResNet) took the deep learning world by storm when Microsoft Research released Deep Residual Learning for Image Recognition. In the 2015 ImageNet and COCO competitions, which covered image classification, object detection, and semantic segmentation, these networks led to 1st-place winning entries in all five main tracks. The robustness of ResNets has since been proven by various visual and non-visual tasks. The Network depth is of crucial importance in neural network architectures, but deeper networks are more difficult to train. The residual learning framework eases the training of these networks, and enables them to be substantially deeper, leading to improved performance in both visual and non-visual tasks.
The classifier has been trained on 2350 images, split equally in two classes. The dataset consists mostly of volounteers' selfies and an external Chinese dataset available on https://github.com/X-zhangyang/Real-World-Masked-Face-Dataset. Model was validated on 784 images, and then tested on another 784 images. Class equality was preserved and the test accuracy was 0.985%. We are constanly working on upgrading the quantity of data batches and the diversity of characters and perspectives, therefore improving the classifier. Classifier's accuracy should be tested on an external, truly random footage, which we are yet to acquire.

To detect the distance of peoples from the camera, the triangle similarity technique is used. During the camera calibration an image of a person with the head height H (we have assumed that the average height of humans head is 22 centimetres) has to be captured as a reference in a specified distance D (in centimetres) from the camera. After measuring the pixel height P of the person's head on the reference image, these values can be used to calculate the focal length of the camera with this formula:
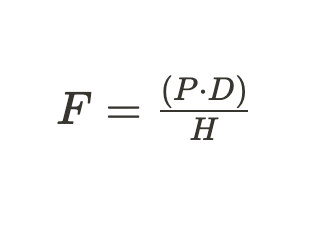
After calculating the focal length of the camera we can use a conversion of the formula to calculate the distance of the camera to different persons on each frame of our video stream.
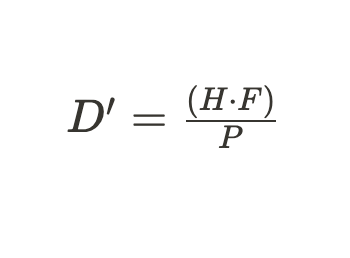
Since there can be n people detected in a video and we want to measure the distance between these peoples, the euclidean distance is calculated between the mid-points of the bounding boxes of all the detected faces. If the distance between two people is less than 150 centimetres, a red bounding box is displayed around the face indicating that they are not maintaining social distance.
This project was part of the ai engineer bootcamp at strive


